Subsystems
This section consists brief description of the subsystems that make up GNUnet. This image is giving an overview over system dependencies and interactions.

CADET - Decentralized End-to-end Transport
The Confidential Ad-hoc Decentralized End-to-end Transport (CADET) subsystem in GNUnet is responsible for secure end-to-end communications between nodes in the GNUnet overlay network. CADET builds on the CORE subsystem, which provides for the link-layer communication, by adding routing, forwarding, and additional security to the connections. CADET offers the same cryptographic services as CORE, but on an end-to-end level. This is done so peers retransmitting traffic on behalf of other peers cannot access the payload data.
CADET provides confidentiality with so-called perfect forward secrecy; we use ECDHE powered by Curve25519 for the key exchange and then use symmetric encryption, encrypting with both AES-256 and Twofish
authentication is achieved by signing the ephemeral keys using Ed25519, a deterministic variant of ECDSA
integrity protection (using SHA-512 to do encrypt-then-MAC, although only 256 bits are sent to reduce overhead)
replay protection (using nonces, timestamps, challenge-response, message counters and ephemeral keys)
liveness (keep-alive messages, timeout)
Additional to the CORE-like security benefits, CADET offers other properties that make it a more universal service than CORE.
CADET can establish channels to arbitrary peers in GNUnet. If a peer is not immediately reachable, CADET will find a path through the network and ask other peers to retransmit the traffic on its behalf.
CADET offers (optional) reliability mechanisms. In a reliable channel traffic is guaranteed to arrive complete, unchanged and in-order.
CADET takes care of flow and congestion control mechanisms, not allowing the sender to send more traffic than the receiver or the network are able to process.
CORE - GNUnet link layer
The CORE subsystem in GNUnet is responsible for securing link-layer communications between nodes in the GNUnet overlay network. CORE builds on the TRANSPORT subsystem which provides for the actual, insecure, unreliable link-layer communication (for example, via UDP or WLAN), and then adds fundamental security to the connections:
confidentiality with so-called perfect forward secrecy; we use ECDHE (Elliptic-curve Diffie—Hellman) powered by Curve25519 (Curve25519) for the key exchange and then use symmetric encryption, encrypting with both AES-256 (AES-256) and Twofish (Twofish)
authentication is achieved by signing the ephemeral keys using Ed25519 (Ed25519), a deterministic variant of ECDSA (ECDSA)
integrity protection (using SHA-512 (SHA-512) to do encrypt-then-MAC (encrypt-then-MAC))
Replay (replay) protection (using nonces, timestamps, challenge-response, message counters and ephemeral keys)
liveness (keep-alive messages, timeout)
Limitations Limitations ———–
CORE does not perform routing; using CORE it is only possible to communicate with peers that happen to already be "directly" connected with each other. CORE also does not have an API to allow applications to establish such "direct" connections — for this, applications can ask TRANSPORT, but TRANSPORT might not be able to establish a "direct" connection. The TOPOLOGY subsystem is responsible for trying to keep a few "direct" connections open at all times. Applications that need to talk to particular peers should use the CADET subsystem, as it can establish arbitrary "indirect" connections.
Because CORE does not perform routing, CORE must only be used directly by applications that either perform their own routing logic (such as anonymous file-sharing) or that do not require routing, for example because they are based on flooding the network. CORE communication is unreliable and delivery is possibly out-of-order. Applications that require reliable communication should use the CADET service. Each application can only queue one message per target peer with the CORE service at any time; messages cannot be larger than approximately 63 kilobytes. If messages are small, CORE may group multiple messages (possibly from different applications) prior to encryption. If permitted by the application (using the cork option), CORE may delay transmissions to facilitate grouping of multiple small messages. If cork is not enabled, CORE will transmit the message as soon as TRANSPORT allows it (TRANSPORT is responsible for limiting bandwidth and congestion control). CORE does not allow flow control; applications are expected to process messages at line-speed. If flow control is needed, applications should use the CADET service.
When is a peer "connected"?
In addition to the security features mentioned above, CORE also provides
one additional key feature to applications using it, and that is a
limited form of protocol-compatibility checking. CORE distinguishes
between TRANSPORT-level connections (which enable communication with
other peers) and application-level connections. Applications using the
CORE API will (typically) learn about application-level connections from
CORE, and not about TRANSPORT-level connections. When a typical
application uses CORE, it will specify a set of message types (from
gnunet_protocols.h) that it understands. CORE will then notify the
application about connections it has with other peers if and only if
those applications registered an intersecting set of message types with
their CORE service. Thus, it is quite possible that CORE only exposes a
subset of the established direct connections to a particular application
— and different applications running above CORE might see different
sets of connections at the same time.
A special case are applications that do not register a handler for any
message type. CORE assumes that these applications merely want to
monitor connections (or "all" messages via other callbacks) and will
notify those applications about all connections. This is used, for
example, by the gnunet-core command-line tool to display the active
connections. Note that it is also possible that the TRANSPORT service
has more active connections than the CORE service, as the CORE service
first has to perform a key exchange with connecting peers before
exchanging information about supported message types and notifying
applications about the new connection.
.. _Distributed-Hash-Table-_0028DHT_0029:
DHT - Distributed Hash Table
GNUnet includes a generic distributed hash table that can be used by developers building P2P applications in the framework. This section documents high-level features and how developers are expected to use the DHT. We have a research paper detailing how the DHT works. Also, Nate’s thesis includes a detailed description and performance analysis (in chapter 6). [R5N2011] [EVANS2011]
Key features of GNUnet’s DHT include:
stores key-value pairs with values up to (approximately) 63k in size
works with many underlay network topologies (small-world, random graph), underlay does not need to be a full mesh / clique
support for extended queries (more than just a simple ‘key’), filtering duplicate replies within the network (bloomfilter) and content validation (for details, please read the subsection on the block library)
can (optionally) return paths taken by the PUT and GET operations to the application
provides content replication to handle churn
GNUnet’s DHT is randomized and unreliable. Unreliable means that there is no strict guarantee that a value stored in the DHT is always found — values are only found with high probability. While this is somewhat true in all P2P DHTs, GNUnet developers should be particularly wary of this fact (this will help you write secure, fault-tolerant code). Thus, when writing any application using the DHT, you should always consider the possibility that a value stored in the DHT by you or some other peer might simply not be returned, or returned with a significant delay. Your application logic must be written to tolerate this (naturally, some loss of performance or quality of service is expected in this case).
Block library and plugins
What is a Block?
Blocks are small (< 63k) pieces of data stored under a key (struct GNUNET_HashCode). Blocks have a type (enum GNUNET_BlockType) which defines their data format. Blocks are used in GNUnet as units of static data exchanged between peers and stored (or cached) locally. Uses of blocks include file-sharing (the files are broken up into blocks), the VPN (DNS information is stored in blocks) and the DHT (all information in the DHT and meta-information for the maintenance of the DHT are both stored using blocks). The block subsystem provides a few common functions that must be available for any type of block.
FS — File sharing over GNUnet
This chapter describes the details of how the file-sharing service works. As with all services, it is split into an API (libgnunetfs), the service process (gnunet-service-fs) and user interface(s). The file-sharing service uses the datastore service to store blocks and the DHT (and indirectly datacache) for lookups for non-anonymous file-sharing. Furthermore, the file-sharing service uses the block library (and the block fs plugin) for validation of DHT operations.
In contrast to many other services, libgnunetfs is rather complex since the client library includes a large number of high-level abstractions; this is necessary since the FS service itself largely only operates on the block level. The FS library is responsible for providing a file-based abstraction to applications, including directories, meta data, keyword search, verification, and so on.
The method used by GNUnet to break large files into blocks and to use keyword search is called the "Encoding for Censorship Resistant Sharing" (ECRS). ECRS is largely implemented in the fs library; block validation is also reflected in the block FS plugin and the FS service. ECRS on-demand encoding is implemented in the FS service.
Note
The documentation in this chapter is quite incomplete.
ECRS — Encoding for Censorship-Resistant Sharing ECRS — Encoding for Censorship-Resistant Sharing ————————————————
When GNUnet shares files, it uses a content encoding that is called ECRS, the Encoding for Censorship-Resistant Sharing. Most of ECRS is described in the (so far unpublished) research paper attached to this page. ECRS obsoletes the previous ESED and ESED II encodings which were used in GNUnet before version 0.7.0. The rest of this page assumes that the reader is familiar with the attached paper. What follows is a description of some minor extensions that GNUnet makes over what is described in the paper. The reason why these extensions are not in the paper is that we felt that they were obvious or trivial extensions to the original scheme and thus did not warrant space in the research report.
Todo
Find missing link to file system paper.
GNS - the GNU Name system
The GNU Name System (GNS) is a decentralized database that enables users to securely resolve names to values. Names can be used to identify other users (for example, in social networking), or network services (for example, VPN services running at a peer in GNUnet, or purely IP-based services on the Internet). Users interact with GNS by typing in a hostname that ends in a top-level domain that is configured in the “GNS” section, matches an identity of the user or ends in a Base32-encoded public key.
Videos giving an overview of most of the GNS and the motivations behind it is available here and here. The remainder of this chapter targets developers that are familiar with high level concepts of GNS as presented in these talks.
Todo
Link to videos and GNS talks?
GNS-aware applications should use the GNS resolver to obtain the respective records that are stored under that name in GNS. Each record consists of a type, value, expiration time and flags.
The type specifies the format of the value. Types below 65536 correspond to DNS record types, larger values are used for GNS-specific records. Applications can define new GNS record types by reserving a number and implementing a plugin (which mostly needs to convert the binary value representation to a human-readable text format and vice-versa). The expiration time specifies how long the record is to be valid. The GNS API ensures that applications are only given non-expired values. The flags are typically irrelevant for applications, as GNS uses them internally to control visibility and validity of records.
Records are stored along with a signature. The signature is generated using the private key of the authoritative zone. This allows any GNS resolver to verify the correctness of a name-value mapping.
Internally, GNS uses the NAMECACHE to cache information obtained from other users, the NAMESTORE to store information specific to the local users, and the DHT to exchange data between users. A plugin API is used to enable applications to define new GNS record types.
NAMECACHE — DHT caching of GNS results
The NAMECACHE subsystem is responsible for caching (encrypted) resolution results of the GNU Name System (GNS). GNS makes zone information available to other users via the DHT. However, as accessing the DHT for every lookup is expensive (and as the DHT’s local cache is lost whenever the peer is restarted), GNS uses the NAMECACHE as a more persistent cache for DHT lookups. Thus, instead of always looking up every name in the DHT, GNS first checks if the result is already available locally in the NAMECACHE. Only if there is no result in the NAMECACHE, GNS queries the DHT. The NAMECACHE stores data in the same (encrypted) format as the DHT. It thus makes no sense to iterate over all items in the NAMECACHE – the NAMECACHE does not have a way to provide the keys required to decrypt the entries.
Blocks in the NAMECACHE share the same expiration mechanism as blocks in the DHT – the block expires wheneever any of the records in the (encrypted) block expires. The expiration time of the block is the only information stored in plaintext. The NAMECACHE service internally performs all of the required work to expire blocks, clients do not have to worry about this. Also, given that NAMECACHE stores only GNS blocks that local users requested, there is no configuration option to limit the size of the NAMECACHE. It is assumed to be always small enough (a few MB) to fit on the drive.
The NAMECACHE supports the use of different database backends via a plugin API.
NAMESTORE — Storage of local GNS zones
The NAMESTORE subsystem provides persistent storage for local GNS zone information. All local GNS zone information are managed by NAMESTORE. It provides both the functionality to administer local GNS information (e.g. delete and add records) as well as to retrieve GNS information (e.g to list name information in a client). NAMESTORE does only manage the persistent storage of zone information belonging to the user running the service: GNS information from other users obtained from the DHT are stored by the NAMECACHE subsystem.
NAMESTORE uses a plugin-based database backend to store GNS information with good performance. Here sqlite and PostgreSQL are supported database backends. NAMESTORE clients interact with the IDENTITY subsystem to obtain cryptographic information about zones based on egos as described with the IDENTITY subsystem, but internally NAMESTORE refers to zones using the respective private key.
NAMESTORE is queried and monitored by the ZONEMASTER service which periodically publishes public records of GNS zones. ZONEMASTER also collaborates with the NAMECACHE subsystem and stores zone information when local information are modified in the NAMECACHE cache to increase look-up performance for local information and to enable local access to private records in zones through GNS.
NAMESTORE provides functionality to look-up and store records, to iterate over a specific or all zones and to monitor zones for changes. NAMESTORE functionality can be accessed using the NAMESTORE C API, the NAMESTORE REST API, or the NAMESTORE command line tool.
HOSTLIST — HELLO bootstrapping and gossip
Peers in the GNUnet overlay network need address information so that they can connect with other peers. GNUnet uses so called HELLO messages to store and exchange peer addresses. GNUnet provides several methods for peers to obtain this information:
out-of-band exchange of HELLO messages (manually, using for example gnunet-core)
HELLO messages shipped with GNUnet (automatic with distribution)
UDP neighbor discovery in LAN (IPv4 broadcast, IPv6 multicast)
topology gossiping (learning from other peers we already connected to), and
the HOSTLIST daemon covered in this section, which is particularly relevant for bootstrapping new peers.
New peers have no existing connections (and thus cannot learn from gossip among peers), may not have other peers in their LAN and might be started with an outdated set of HELLO messages from the distribution. In this case, getting new peers to connect to the network requires either manual effort or the use of a HOSTLIST to obtain HELLOs.
HELLOs
The basic information peers require to connect to other peers are contained in so called HELLO messages you can think of as a business card. Besides the identity of the peer (based on the cryptographic public key) a HELLO message may contain address information that specifies ways to contact a peer. By obtaining HELLO messages, a peer can learn how to contact other peers.
Overview for the HOSTLIST subsystem
The HOSTLIST subsystem provides a way to distribute and obtain contact
information to connect to other peers using a simple HTTP GET request.
Its implementation is split in three parts, the main file for the
daemon itself (gnunet-daemon-hostlist.c), the HTTP client used to
download peer information (hostlist-client.c) and the server
component used to provide this information to other peers
(hostlist-server.c). The server is basically a small HTTP web server
(based on GNU libmicrohttpd) which provides a list of HELLOs known to
the local peer for download. The client component is basically a HTTP
client (based on libcurl) which can download hostlists from one or more
websites. The hostlist format is a binary blob containing a sequence of
HELLO messages. Note that any HTTP server can theoretically serve a
hostlist, the built-in hostlist server makes it simply convenient to
offer this service.
Features
The HOSTLIST daemon can:
provide HELLO messages with validated addresses obtained from PEERINFO to download for other peers
download HELLO messages and forward these message to the TRANSPORT subsystem for validation
advertises the URL of this peer’s hostlist address to other peers via gossip
automatically learn about hostlist servers from the gossip of other peers
HOSTLIST - Limitations
The HOSTLIST daemon does not:
verify the cryptographic information in the HELLO messages
verify the address information in the HELLO messages
Interacting with the HOSTLIST daemon
The HOSTLIST subsystem is currently implemented as a daemon, so there is no need for the user to interact with it and therefore there is no command line tool and no API to communicate with the daemon. In the future, we can envision changing this to allow users to manually trigger the download of a hostlist.
Since there is no command line interface to interact with HOSTLIST, the only way to interact with the hostlist is to use STATISTICS to obtain or modify information about the status of HOSTLIST:
$ gnunet-statistics -s hostlist
In particular, HOSTLIST includes a persistent value in statistics that specifies when the hostlist server might be queried next. As this value is exponentially increasing during runtime, developers may want to reset or manually adjust it. Note that HOSTLIST (but not STATISTICS) needs to be shutdown if changes to this value are to have any effect on the daemon (as HOSTLIST does not monitor STATISTICS for changes to the download frequency).
Hostlist security address validation
Since information obtained from other parties cannot be trusted without validation, we have to distinguish between validated and not validated addresses. Before using (and so trusting) information from other parties, this information has to be double-checked (validated). Address validation is not done by HOSTLIST but by the TRANSPORT service.
The HOSTLIST component is functionally located between the PEERINFO and the TRANSPORT subsystem. When acting as a server, the daemon obtains valid (validated) peer information (HELLO messages) from the PEERINFO service and provides it to other peers. When acting as a client, it contacts the HOSTLIST servers specified in the configuration, downloads the (unvalidated) list of HELLO messages and forwards these information to the TRANSPORT server to validate the addresses.
The HOSTLIST daemon The HOSTLIST daemon ——————-
The hostlist daemon is the main component of the HOSTLIST subsystem. It is started by the ARM service and (if configured) starts the HOSTLIST client and server components.
GNUNET_MESSAGE_TYPE_HOSTLIST_ADVERTISEMENT
If the daemon provides a hostlist itself it can advertise it’s own
hostlist to other peers. To do so it sends a
GNUNET_MESSAGE_TYPE_HOSTLIST_ADVERTISEMENT message to other peers
when they connect to this peer on the CORE level. This hostlist
advertisement message contains the URL to access the HOSTLIST HTTP
server of the sender. The daemon may also subscribe to this type of
message from CORE service, and then forward these kind of message to the
HOSTLIST client. The client then uses all available URLs to download
peer information when necessary.
When starting, the HOSTLIST daemon first connects to the CORE subsystem and if hostlist learning is enabled, registers a CORE handler to receive this kind of messages. Next it starts (if configured) the client and server. It passes pointers to CORE connect and disconnect and receive handlers where the client and server store their functions, so the daemon can notify them about CORE events.
To clean up on shutdown, the daemon has a cleaning task, shutting down all subsystems and disconnecting from CORE.
The HOSTLIST server The HOSTLIST server ——————-
The server provides a way for other peers to obtain HELLOs. Basically it is a small web server other peers can connect to and download a list of HELLOs using standard HTTP; it may also advertise the URL of the hostlist to other peers connecting on CORE level.
The HTTP Server
During startup, the server starts a web server listening on the port specified with the HTTPPORT value (default 8080). In addition it connects to the PEERINFO service to obtain peer information. The HOSTLIST server uses the GNUNET_PEERINFO_iterate function to request HELLO information for all peers and adds their information to a new hostlist if they are suitable (expired addresses and HELLOs without addresses are both not suitable) and the maximum size for a hostlist is not exceeded (MAX_BYTES_PER_HOSTLISTS = 500000). When PEERINFO finishes (with a last NULL callback), the server destroys the previous hostlist response available for download on the web server and replaces it with the updated hostlist. The hostlist format is basically a sequence of HELLO messages (as obtained from PEERINFO) without any special tokenization. Since each HELLO message contains a size field, the response can easily be split into separate HELLO messages by the client.
A HOSTLIST client connecting to the HOSTLIST server will receive the
hostlist as an HTTP response and the server will terminate the
connection with the result code HTTP 200 OK. The connection will be
closed immediately if no hostlist is available.
Advertising the URL
The server also advertises the URL to download the hostlist to other
peers if hostlist advertisement is enabled. When a new peer connects and
has hostlist learning enabled, the server sends a
GNUNET_MESSAGE_TYPE_HOSTLIST_ADVERTISEMENT message to this peer
using the CORE service.
HOSTLIST client .. _The-HOSTLIST-client:
The HOSTLIST client
The client provides the functionality to download the list of HELLOs from a set of URLs. It performs a standard HTTP request to the URLs configured and learned from advertisement messages received from other peers. When a HELLO is downloaded, the HOSTLIST client forwards the HELLO to the TRANSPORT service for validation.
The client supports two modes of operation:
download of HELLOs (bootstrapping)
learning of URLs
Bootstrapping
For bootstrapping, it schedules a task to download the hostlist from the set of known URLs. The downloads are only performed if the number of current connections is smaller than a minimum number of connections (at the moment 4). The interval between downloads increases exponentially; however, the exponential growth is limited if it becomes longer than an hour. At that point, the frequency growth is capped at (#number of connections * 1h).
Once the decision has been taken to download HELLOs, the daemon chooses a random URL from the list of known URLs. URLs can be configured in the configuration or be learned from advertisement messages. The client uses a HTTP client library (libcurl) to initiate the download using the libcurl multi interface. Libcurl passes the data to the callback_download function which stores the data in a buffer if space is available and the maximum size for a hostlist download is not exceeded (MAX_BYTES_PER_HOSTLISTS = 500000). When a full HELLO was downloaded, the HOSTLIST client offers this HELLO message to the TRANSPORT service for validation. When the download is finished or failed, statistical information about the quality of this URL is updated.
Learning Learning ^^^^^^^^
The client also manages hostlist advertisements from other peers. The
HOSTLIST daemon forwards GNUNET_MESSAGE_TYPE_HOSTLIST_ADVERTISEMENT
messages to the client subsystem, which extracts the URL from the
message. Next, a test of the newly obtained URL is performed by
triggering a download from the new URL. If the URL works correctly, it
is added to the list of working URLs.
The size of the list of URLs is restricted, so if an additional server is added and the list is full, the URL with the worst quality ranking (determined through successful downloads and number of HELLOs e.g.) is discarded. During shutdown the list of URLs is saved to a file for persistence and loaded on startup. URLs from the configuration file are never discarded.
Usage
To start HOSTLIST by default, it has to be added to the DEFAULTSERVICES section for the ARM services. This is done in the default configuration.
For more information on how to configure the HOSTLIST subsystem see the installation handbook: Configuring the hostlist to bootstrap Configuring your peer to provide a hostlist
IDENTITY — Ego management
Identities of "users" in GNUnet are called egos. Egos can be used as pseudonyms ("fake names") or be tied to an organization (for example, "GNU") or even the actual identity of a human. GNUnet users are expected to have many egos. They might have one tied to their real identity, some for organizations they manage, and more for different domains where they want to operate under a pseudonym.
The IDENTITY service allows users to manage their egos. The identity service manages the private keys egos of the local user; it does not manage identities of other users (public keys). Public keys for other users need names to become manageable. GNUnet uses the GNU Name System (GNS) to give names to other users and manage their public keys securely. This chapter is about the IDENTITY service, which is about the management of private keys.
On the network, an ego corresponds to an ECDSA key (over Curve25519, using RFC 6979, as required by GNS). Thus, users can perform actions under a particular ego by using (signing with) a particular private key. Other users can then confirm that the action was really performed by that ego by checking the signature against the respective public key.
The IDENTITY service allows users to associate a human-readable name with each ego. This way, users can use names that will remind them of the purpose of a particular ego. The IDENTITY service will store the respective private keys and allows applications to access key information by name. Users can change the name that is locally (!) associated with an ego. Egos can also be deleted, which means that the private key will be removed and it thus will not be possible to perform actions with that ego in the future.
Additionally, the IDENTITY subsystem can associate service functions with egos. For example, GNS requires the ego that should be used for the shorten zone. GNS will ask IDENTITY for an ego for the "gns-short" service. The IDENTITY service has a mapping of such service strings to the name of the ego that the user wants to use for this service, for example "my-short-zone-ego".
Finally, the IDENTITY API provides access to a special ego, the anonymous ego. The anonymous ego is special in that its private key is not really private, but fixed and known to everyone. Thus, anyone can perform actions as anonymous. This can be useful as with this trick, code does not have to contain a special case to distinguish between anonymous and pseudonymous egos.
MESSENGER — Room-based end-to-end messaging
The MESSENGER subsystem is responsible for secure end-to-end communication in groups of nodes in the GNUnet overlay network. MESSENGER builds on the CADET subsystem which provides a reliable and secure end-to-end communication between the nodes inside of these groups.
Additionally to the CADET security benefits, MESSENGER provides following properties designed for application level usage:
MESSENGER provides integrity by signing the messages with the users provided ego
MESSENGER adds (optional) forward secrecy by replacing the key pair of the used ego and signing the propagation of the new one with old one (chaining egos)
MESSENGER provides verification of a original sender by checking against all used egos from a member which are currently in active use (active use depends on the state of a member session)
MESSENGER offsers (optional) decentralized message forwarding between all nodes in a group to improve availability and prevent MITM-attacks
MESSENGER handles new connections and disconnections from nodes in the group by reconnecting them preserving an efficient structure for message distribution (ensuring availability and accountablity)
MESSENGER provides replay protection (messages can be uniquely identified via SHA-512, include a timestamp and the hash of the last message)
MESSENGER allows detection for dropped messages by chaining them (messages refer to the last message by their hash) improving accountability
MESSENGER allows requesting messages from other peers explicitly to ensure availability
MESSENGER provides confidentiality by padding messages to few different sizes (512 bytes, 4096 bytes, 32768 bytes and maximal message size from CADET)
MESSENGER adds (optional) confidentiality with ECDHE to exchange and use symmetric encryption, encrypting with both AES-256 and Twofish but allowing only selected members to decrypt (using the receivers ego for ECDHE)
Also MESSENGER provides multiple features with privacy in mind:
MESSENGER allows deleting messages from all peers in the group by the original sender (uses the MESSENGER provided verification)
MESSENGER allows using the publicly known anonymous ego instead of any unique identifying ego
MESSENGER allows your node to decide between acting as host of the used messaging room (sharing your peer’s identity with all nodes in the group) or acting as guest (sharing your peer’s identity only with the nodes you explicitly open a connection to)
MESSENGER handles members independently of the peer’s identity making forwarded messages indistinguishable from directly received ones ( complicating the tracking of messages and identifying its origin)
MESSENGER allows names of members being not unique (also names are optional)
MESSENGER does not include information about the selected receiver of an explicitly encrypted message in its header, complicating it for other members to draw conclusions from communication partners
NSE — Network size estimation
NSE stands for Network Size Estimation. The NSE subsystem provides other subsystems and users with a rough estimate of the number of peers currently participating in the GNUnet overlay. The computed value is not a precise number as producing a precise number in a decentralized, efficient and secure way is impossible. While NSE’s estimate is inherently imprecise, NSE also gives the expected range. For a peer that has been running in a stable network for a while, the real network size will typically (99.7% of the time) be in the range of [2/3 estimate, 3/2 estimate]. We will now give an overview of the algorithm used to calculate the estimate; all of the details can be found in this technical report.
Todo
link to the report.
Motivation
Some subsystems, like DHT, need to know the size of the GNUnet network to optimize some parameters of their own protocol. The decentralized nature of GNUnet makes efficient and securely counting the exact number of peers infeasible. Although there are several decentralized algorithms to count the number of peers in a system, so far there is none to do so securely. Other protocols may allow any malicious peer to manipulate the final result or to take advantage of the system to perform Denial of Service (DoS) attacks against the network. GNUnet’s NSE protocol avoids these drawbacks.
NSE security .. _Security:
Security Security ^^^^^^^^
The NSE subsystem is designed to be resilient against these attacks. It uses proofs of work to prevent one peer from impersonating a large number of participants, which would otherwise allow an adversary to artificially inflate the estimate. The DoS protection comes from the time-based nature of the protocol: the estimates are calculated periodically and out-of-time traffic is either ignored or stored for later retransmission by benign peers. In particular, peers cannot trigger global network communication at will.
Principle Principle ———
The algorithm calculates the estimate by finding the globally closest peer ID to a random, time-based value.
The idea is that the closer the ID is to the random value, the more "densely packed" the ID space is, and therefore, more peers are in the network.
Example
Suppose all peers have IDs between 0 and 100 (our ID space), and the random value is 42. If the closest peer has the ID 70 we can imagine that the average "distance" between peers is around 30 and therefore the are around 3 peers in the whole ID space. On the other hand, if the closest peer has the ID 44, we can imagine that the space is rather packed with peers, maybe as much as 50 of them. Naturally, we could have been rather unlucky, and there is only one peer and happens to have the ID 44. Thus, the current estimate is calculated as the average over multiple rounds, and not just a single sample.
Algorithm
Given that example, one can imagine that the job of the subsystem is to efficiently communicate the ID of the closest peer to the target value to all the other peers, who will calculate the estimate from it.
Target value
The target value itself is generated by hashing the current time, rounded down to an agreed value. If the rounding amount is 1h (default) and the time is 12:34:56, the time to hash would be 12:00:00. The process is repeated each rounding amount (in this example would be every hour). Every repetition is called a round.
Timing
The NSE subsystem has some timing control to avoid everybody broadcasting its ID all at one. Once each peer has the target random value, it compares its own ID to the target and calculates the hypothetical size of the network if that peer were to be the closest. Then it compares the hypothetical size with the estimate from the previous rounds. For each value there is an associated point in the period, let’s call it "broadcast time". If its own hypothetical estimate is the same as the previous global estimate, its "broadcast time" will be in the middle of the round. If its bigger it will be earlier and if its smaller (the most likely case) it will be later. This ensures that the peers closest to the target value start broadcasting their ID the first.
Controlled Flooding
When a peer receives a value, first it verifies that it is closer than the closest value it had so far, otherwise it answers the incoming message with a message containing the better value. Then it checks a proof of work that must be included in the incoming message, to ensure that the other peer’s ID is not made up (otherwise a malicious peer could claim to have an ID of exactly the target value every round). Once validated, it compares the broadcast time of the received value with the current time and if it’s not too early, sends the received value to its neighbors. Otherwise it stores the value until the correct broadcast time comes. This prevents unnecessary traffic of sub-optimal values, since a better value can come before the broadcast time, rendering the previous one obsolete and saving the traffic that would have been used to broadcast it to the neighbors.
Calculating the estimate
Once the closest ID has been spread across the network each peer gets the exact distance between this ID and the target value of the round and calculates the estimate with a mathematical formula described in the tech report. The estimate generated with this method for a single round is not very precise. Remember the case of the example, where the only peer is the ID 44 and we happen to generate the target value 42, thinking there are 50 peers in the network. Therefore, the NSE subsystem remembers the last 64 estimates and calculates an average over them, giving a result of which usually has one bit of uncertainty (the real size could be half of the estimate or twice as much). Note that the actual network size is calculated in powers of two of the raw input, thus one bit of uncertainty means a factor of two in the size estimate.
PEERINFO — Persistent HELLO storage
The PEERINFO subsystem is used to store verified (validated) information about known peers in a persistent way. It obtains these addresses for example from TRANSPORT service which is in charge of address validation. Validation means that the information in the HELLO message are checked by connecting to the addresses and performing a cryptographic handshake to authenticate the peer instance stating to be reachable with these addresses. Peerinfo does not validate the HELLO messages itself but only stores them and gives them to interested clients.
As future work, we think about moving from storing just HELLO messages to providing a generic persistent per-peer information store. More and more subsystems tend to need to store per-peer information in persistent way. To not duplicate this functionality we plan to provide a PEERSTORE service providing this functionality.
PEERINFO - Features
Persistent storage
Client notification mechanism on update
Periodic clean up for expired information
Differentiation between public and friend-only HELLO
PEERINFO - Limitations
Does not perform HELLO validation
DeveloperPeer Information
The PEERINFO subsystem stores these information in the form of HELLO messages you can think of as business cards. These HELLO messages contain the public key of a peer and the addresses a peer can be reached under. The addresses include an expiration date describing how long they are valid. This information is updated regularly by the TRANSPORT service by revalidating the address. If an address is expired and not renewed, it can be removed from the HELLO message.
Some peer do not want to have their HELLO messages distributed to other
peers, especially when GNUnet’s friend-to-friend modus is enabled. To
prevent this undesired distribution. PEERINFO distinguishes between
public and friend-only HELLO messages. Public HELLO messages can be
freely distributed to other (possibly unknown) peers (for example using
the hostlist, gossiping, broadcasting), whereas friend-only HELLO
messages may not be distributed to other peers. Friend-only HELLO
messages have an additional flag friend_only set internally. For
public HELLO message this flag is not set. PEERINFO does and cannot not
check if a client is allowed to obtain a specific HELLO type.
The HELLO messages can be managed using the GNUnet HELLO library. Other GNUnet systems can obtain these information from PEERINFO and use it for their purposes. Clients are for example the HOSTLIST component providing these information to other peers in form of a hostlist or the TRANSPORT subsystem using these information to maintain connections to other peers.
Startup
During startup the PEERINFO services loads persistent HELLOs from disk.
First PEERINFO parses the directory configured in the HOSTS value of the
PEERINFO configuration section to store PEERINFO information. For
all files found in this directory valid HELLO messages are extracted. In
addition it loads HELLO messages shipped with the GNUnet distribution.
These HELLOs are used to simplify network bootstrapping by providing
valid peer information with the distribution. The use of these HELLOs
can be prevented by setting the USE_INCLUDED_HELLOS in the
PEERINFO configuration section to NO. Files containing invalid
information are removed.
Managing Information
The PEERINFO services stores information about known PEERS and a single HELLO message for every peer. A peer does not need to have a HELLO if no information are available. HELLO information from different sources, for example a HELLO obtained from a remote HOSTLIST and a second HELLO stored on disk, are combined and merged into one single HELLO message per peer which will be given to clients. During this merge process the HELLO is immediately written to disk to ensure persistence.
PEERINFO in addition periodically scans the directory where information are stored for empty HELLO messages with expired TRANSPORT addresses. This periodic task scans all files in the directory and recreates the HELLO messages it finds. Expired TRANSPORT addresses are removed from the HELLO and if the HELLO does not contain any valid addresses, it is discarded and removed from the disk.
Obtaining Information
When a client requests information from PEERINFO, PEERINFO performs a lookup for the respective peer or all peers if desired and transmits this information to the client. The client can specify if friend-only HELLOs have to be included or not and PEERINFO filters the respective HELLO messages before transmitting information.
To notify clients about changes to PEERINFO information, PEERINFO maintains a list of clients interested in this notifications. Such a notification occurs if a HELLO for a peer was updated (due to a merge for example) or a new peer was added.
PEERSTORE — Extensible local persistent data storage
GNUnet’s PEERSTORE subsystem offers persistent per-peer storage for other GNUnet subsystems. GNUnet subsystems can use PEERSTORE to persistently store and retrieve arbitrary data. Each data record stored with PEERSTORE contains the following fields:
subsystem: Name of the subsystem responsible for the record.
peerid: Identity of the peer this record is related to.
key: a key string identifying the record.
value: binary record value.
expiry: record expiry date.
Functionality
Subsystems can store any type of value under a (subsystem, peerid, key) combination. A "replace" flag set during store operations forces the PEERSTORE to replace any old values stored under the same (subsystem, peerid, key) combination with the new value. Additionally, an expiry date is set after which the record is *possibly* deleted by PEERSTORE.
Subsystems can iterate over all values stored under any of the following combination of fields:
(subsystem)
(subsystem, peerid)
(subsystem, key)
(subsystem, peerid, key)
Subsystems can also request to be notified about any new values stored under a (subsystem, peerid, key) combination by sending a "watch" request to PEERSTORE.
Architecture
PEERSTORE implements the following components:
PEERSTORE service: Handles store, iterate and watch operations.
PEERSTORE API: API to be used by other subsystems to communicate and issue commands to the PEERSTORE service.
PEERSTORE plugins: Handles the persistent storage. At the moment, only an "sqlite" plugin is implemented.
REGEX — Service discovery using regular expressions
Using the REGEX subsystem, you can discover peers that offer a particular service using regular expressions. The peers that offer a service specify it using a regular expressions. Peers that want to patronize a service search using a string. The REGEX subsystem will then use the DHT to return a set of matching offerers to the patrons.
For the technical details, we have Max’s defense talk and Max’s Master’s thesis.
Note
An additional publication is under preparation and available to team members (in Git).
Todo
Missing links to Max’s talk and Master’s thesis
How to run the regex profiler
The gnunet-regex-profiler can be used to profile the usage of mesh/regex for a given set of regular expressions and strings. Mesh/regex allows you to announce your peer ID under a certain regex and search for peers matching a particular regex using a string. See szengel2012ms for a full introduction.
First of all, the regex profiler uses GNUnet testbed, thus all the implications for testbed also apply to the regex profiler (for example you need password-less ssh login to the machines listed in your hosts file).
Configuration
Moreover, an appropriate configuration file is needed. In the following paragraph the important details are highlighted.
Announcing of the regular expressions is done by the gnunet-daemon-regexprofiler, therefore you have to make sure it is started, by adding it to the START_ON_DEMAND set of ARM:
[regexprofiler]
START_ON_DEMAND = YES
Furthermore you have to specify the location of the binary:
[regexprofiler]
# Location of the gnunet-daemon-regexprofiler binary.
BINARY = /home/szengel/gnunet/src/mesh/.libs/gnunet-daemon-regexprofiler
# Regex prefix that will be applied to all regular expressions and
# search string.
REGEX_PREFIX = "GNVPN-0001-PAD"
When running the profiler with a large scale deployment, you probably want to reduce the workload of each peer. Use the following options to do this.
[dht]
# Force network size estimation
FORCE_NSE = 1
[dhtcache]
DATABASE = heap
# Disable RC-file for Bloom filter? (for benchmarking with limited IO
# availability)
DISABLE_BF_RC = YES
# Disable Bloom filter entirely
DISABLE_BF = YES
[nse]
# Minimize proof-of-work CPU consumption by NSE
WORKBITS = 1
Options
To finally run the profiler some options and the input data need to be specified on the command line.
gnunet-regex-profiler -c config-file -d log-file -n num-links \
-p path-compression-length -s search-delay -t matching-timeout \
-a num-search-strings hosts-file policy-dir search-strings-file
Where...
...
config-filemeans the configuration file created earlier....
log-fileis the file where to write statistics output....
num-linksindicates the number of random links between started peers....
path-compression-lengthis the maximum path compression length in the DFA....
search-delaytime to wait between peers finished linking and starting to match strings....
matching-timeouttimeout after which to cancel the searching....
num-search-stringsnumber of strings in the search-strings-file.... the
hosts-fileshould contain a list of hosts for the testbed, one per line in the following format:user@host_ip:port
... the
policy-diris a folder containing text files containing one or more regular expressions. A peer is started for each file in that folder and the regular expressions in the corresponding file are announced by this peer.... the
search-strings-fileis a text file containing search strings, one in each line.
You can create regular expressions and search strings for every AS in the Internet using the attached scripts. You need one of the CAIDA routeviews prefix2as data files for this. Run
create_regex.py <filename> <output path>
to create the regular expressions and
create_strings.py <input path> <outfile>
to create a search strings file from the previously created regular expressions.
REST — RESTful GNUnet Web APIs
Todo
Define REST
Using the REST subsystem, you can expose REST-based APIs or services. The REST service is designed as a pluggable architecture.
Configuration
The REST service can be configured in various ways. The reference config
file can be found in src/rest/rest.conf:
[rest]
REST_PORT=7776
REST_ALLOW_HEADERS=Authorization,Accept,Content-Type
REST_ALLOW_ORIGIN=*
REST_ALLOW_CREDENTIALS=true
The port as well as CORS (cross-origin resource sharing) headers that are supposed to be advertised by the rest service are configurable.
REVOCATION — Ego key revocation
The REVOCATION subsystem is responsible for key revocation of Egos. If a user learns that their private key has been compromised or has lost it, they can use the REVOCATION system to inform all of the other users that their private key is no longer valid. The subsystem thus includes ways to query for the validity of keys and to propagate revocation messages.
Dissemination
When a revocation is performed, the revocation is first of all disseminated by flooding the overlay network. The goal is to reach every peer, so that when a peer needs to check if a key has been revoked, this will be purely a local operation where the peer looks at its local revocation list. Flooding the network is also the most robust form of key revocation — an adversary would have to control a separator of the overlay graph to restrict the propagation of the revocation message. Flooding is also very easy to implement — peers that receive a revocation message for a key that they have never seen before simply pass the message to all of their neighbours.
Flooding can only distribute the revocation message to peers that are online. In order to notify peers that join the network later, the revocation service performs efficient set reconciliation over the sets of known revocation messages whenever two peers (that both support REVOCATION dissemination) connect. The SET service is used to perform this operation efficiently.
Revocation Message Design Requirements
However, flooding is also quite costly, creating O(|E|) messages on a network with |E| edges. Thus, revocation messages are required to contain a proof-of-work, the result of an expensive computation (which, however, is cheap to verify). Only peers that have expended the CPU time necessary to provide this proof will be able to flood the network with the revocation message. This ensures that an attacker cannot simply flood the network with millions of revocation messages. The proof-of-work required by GNUnet is set to take days on a typical PC to compute; if the ability to quickly revoke a key is needed, users have the option to pre-compute revocation messages to store off-line and use instantly after their key has expired.
Revocation messages must also be signed by the private key that is being revoked. Thus, they can only be created while the private key is in the possession of the respective user. This is another reason to create a revocation message ahead of time and store it in a secure location.
RPS — Random peer sampling
In literature, Random Peer Sampling (RPS) refers to the problem of reliably [1] drawing random samples from an unstructured p2p network.
Doing so in a reliable manner is not only hard because of inherent problems but also because of possible malicious peers that could try to bias the selection.
It is useful for all kind of gossip protocols that require the selection of random peers in the whole network like gathering statistics, spreading and aggregating information in the network, load balancing and overlay topology management.
The approach chosen in the RPS service implementation in GNUnet follows the Brahms design.
The current state is "work in progress". There are a lot of things that need to be done, primarily finishing the experimental evaluation and a re-design of the API.
The abstract idea is to subscribe to connect to/start the RPS service and request random peers that will be returned when they represent a random selection from the whole network with high probability.
An additional feature to the original Brahms-design is the selection of sub-groups: The GNUnet implementation of RPS enables clients to ask for random peers from a group that is defined by a common shared secret. (The secret could of course also be public, depending on the use-case.)
Another addition to the original protocol was made: The sampler mechanism that was introduced in Brahms was slightly adapted and used to actually sample the peers and returned to the client. This is necessary as the original design only keeps peers connected to random other peers in the network. In order to return random peers to client requests independently random, they cannot be drawn from the connected peers. The adapted sampler makes sure that each request for random peers is independent from the others.
Brahms
The high-level concept of Brahms is two-fold: Combining push-pull gossip with locally fixing a assumed bias using cryptographic min-wise permutations. The central data structure is the view - a peer’s current local sample. This view is used to select peers to push to and pull from. This simple mechanism can be biased easily. For this reason Brahms ‘fixes’ the bias by using the so-called sampler. A data structure that takes a list of elements as input and outputs a random one of them independently of the frequency in the input set. Both an element that was put into the sampler a single time and an element that was put into it a million times have the same probability of being the output. This is achieved with exploiting min-wise independent permutations. In the RPS service we use HMACs: On the initialisation of a sampler element, a key is chosen at random. On each input the HMAC with the random key is computed. The sampler element keeps the element with the minimal HMAC.
In order to fix the bias in the view, a fraction of the elements in the view are sampled through the sampler from the random stream of peer IDs.
According to the theoretical analysis of Bortnikov et al. this suffices to keep the network connected and having random peers in the view.
STATISTICS — Runtime statistics publication
In GNUnet, the STATISTICS subsystem offers a central place for all subsystems to publish unsigned 64-bit integer run-time statistics. Keeping this information centrally means that there is a unified way for the user to obtain data on all subsystems, and individual subsystems do not have to always include a custom data export method for performance metrics and other statistics. For example, the TRANSPORT system uses STATISTICS to update information about the number of directly connected peers and the bandwidth that has been consumed by the various plugins. This information is valuable for diagnosing connectivity and performance issues.
Following the GNUnet service architecture, the STATISTICS subsystem is divided into an API which is exposed through the header gnunet_statistics_service.h and the STATISTICS service gnunet-service-statistics. The gnunet-statistics command-line tool can be used to obtain (and change) information about the values stored by the STATISTICS service. The STATISTICS service does not communicate with other peers.
Data is stored in the STATISTICS service in the form of tuples (subsystem, name, value, persistence). The subsystem determines to which other GNUnet’s subsystem the data belongs. name is the name through which value is associated. It uniquely identifies the record from among other records belonging to the same subsystem. In some parts of the code, the pair (subsystem, name) is called a statistic as it identifies the values stored in the STATISTCS service.The persistence flag determines if the record has to be preserved across service restarts. A record is said to be persistent if this flag is set for it; if not, the record is treated as a non-persistent record and it is lost after service restart. Persistent records are written to and read from the file statistics.data before shutdown and upon startup. The file is located in the HOME directory of the peer.
An anomaly of the STATISTICS service is that it does not terminate immediately upon receiving a shutdown signal if it has any clients connected to it. It waits for all the clients that are not monitors to close their connections before terminating itself. This is to prevent the loss of data during peer shutdown — delaying the STATISTICS service shutdown helps other services to store important data to STATISTICS during shutdown.
TRANSPORT-NG — Next-generation transport management
The current GNUnet TRANSPORT architecture is rooted in the GNUnet 0.4 design of using plugins for the actual transmission operations and the ATS subsystem to select a plugin and allocate bandwidth. The following key issues have been identified with this design:
Bugs in one plugin can affect the TRANSPORT service and other plugins. There is at least one open bug that affects sockets, where the origin is difficult to pinpoint due to the large code base.
Relevant operating system default configurations often impose a limit of 1024 file descriptors per process. Thus, one plugin may impact other plugin’s connectivity choices.
Plugins are required to offer bi-directional connectivity. However, firewalls (incl. NAT boxes) and physical environments sometimes only allow uni-directional connectivity, which then currently cannot be utilized at all.
Distance vector routing was implemented in 209 but shortly afterwards broken and due to the complexity of implementing it as a plugin and dealing with the resource allocation consequences was never useful.
Most existing plugins communicate completely using cleartext, exposing metad data (message size) and making it easy to fingerprint and possibly block GNUnet traffic.
Various NAT traversal methods are not supported.
The service logic is cluttered with "manipulation" support code for TESTBED to enable faking network characteristics like lossy connections or firewewalls.
Bandwidth allocation is done in ATS, requiring the duplication of state and resulting in much delayed allocation decisions. As a result, often available bandwidth goes unused. Users are expected to manually configure bandwidth limits, instead of TRANSPORT using congestion control to adapt automatically.
TRANSPORT is difficult to test and has bad test coverage.
HELLOs include an absolute expiration time. Nodes with unsynchronized clocks cannot connect.
Displaying the contents of a HELLO requires the respective plugin as the plugin-specific data is encoded in binary. This also complicates logging.
Design goals of TNG
In order to address the above issues, we want to:
Move plugins into separate processes which we shall call communicators. Communicators connect as clients to the transport service.
TRANSPORT should be able to utilize any number of communicators to the same peer at the same time.
TRANSPORT should be responsible for fragmentation, retransmission, flow- and congestion-control. Users should no longer have to configure bandwidth limits: TRANSPORT should detect what is available and use it.
Communicators should be allowed to be uni-directional and unreliable. TRANSPORT shall create bi-directional channels from this whenever possible.
DV should no longer be a plugin, but part of TRANSPORT.
TRANSPORT should provide communicators help communicating, for example in the case of uni-directional communicators or the need for out-of-band signalling for NAT traversal. We call this functionality backchannels.
Transport manipulation should be signalled to CORE on a per-message basis instead of an approximate bandwidth.
CORE should signal performance requirements (reliability, latency, etc.) on a per-message basis to TRANSPORT. If possible, TRANSPORT should consider those options when scheduling messages for transmission.
HELLOs should be in a human-readable format with monotonic time expirations.
The new architecture is planned as follows:
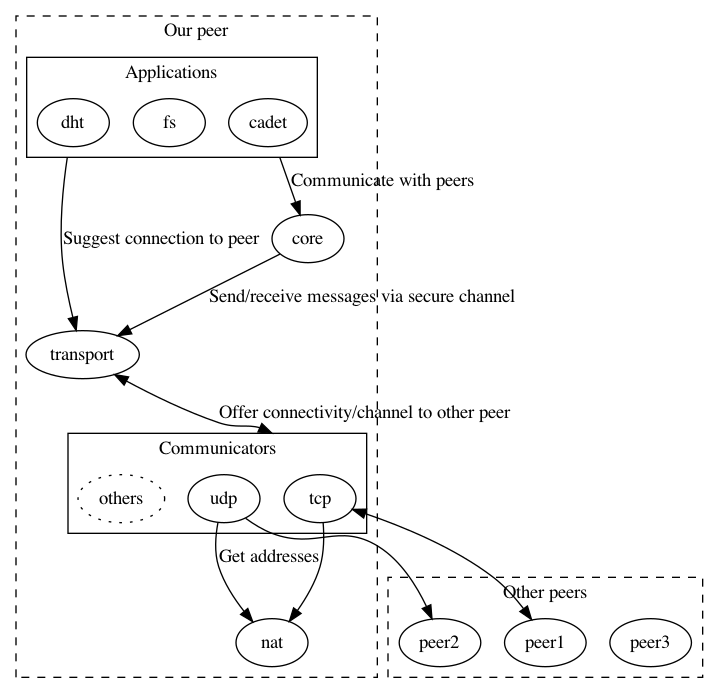
TRANSPORT’s main objective is to establish bi-directional virtual links using a variety of possibly uni-directional communicators. Links undergo the following steps:
Communicator informs TRANSPORT A that a queue (direct neighbour) is available, or equivalently TRANSPORT A discovers a (DV) path to a target B.
TRANSPORT A sends a challenge to the target peer, trying to confirm that the peer can receive. FIXME: This is not implemented properly for DV. Here we should really take a validated DVH and send a challenge exactly down that path!
The other TRANSPORT, TRANSPORT B, receives the challenge, and sends back a response, possibly using a dierent path. If TRANSPORT B does not yet have a virtual link to A, it must try to establish a virtual link.
Upon receiving the response, TRANSPORT A creates the virtual link. If the response included a challenge, TRANSPORT A must respond to this challenge as well, eectively re-creating the TCP 3-way handshake (just with longer challenge values).
HELLO-NG
HELLOs change in three ways. First of all, communicators encode the respective addresses in a human-readable URL-like string. This way, we do no longer require the communicator to print the contents of a HELLO. Second, HELLOs no longer contain an expiration time, only a creation time. The receiver must only compare the respective absolute values. So given a HELLO from the same sender with a larger creation time, then the old one is no longer valid. This also obsoletes the need for the gnunet-hello binary to set HELLO expiration times to never. Third, a peer no longer generates one big HELLO that always contains all of the addresses. Instead, each address is signed individually and shared only over the address scopes where it makes sense to share the address. In particular, care should be taken to not share MACs across the Internet and confine their use to the LAN. As each address is signed separately, having multiple addresses valid at the same time (given the new creation time expiration logic) requires that those addresses must have exactly the same creation time. Whenever that monotonic time is increased, all addresses must be re-signed and re-distributed.
Priorities and preferences
In the new design, TRANSPORT adopts a feature (which was previously already available in CORE) of the MQ API to allow applications to specify priorities and preferences per message (or rather, per MQ envelope). The (updated) MQ API allows applications to specify one of four priority levels as well as desired preferences for transmission by setting options on an envelope. These preferences currently are:
GNUNET_MQ_PREF_UNRELIABLE: Disables TRANSPORT waiting for ACKS on unreliable channels like UDP. Now it is fire and forget. These messages then cannot be used for RTT estimates either.
GNUNET_MQ_PREF_LOW_LATENCY: Directs TRANSPORT to select the lowest-latency transmission choices possible.
GNUNET_MQ_PREF_CORK_ALLOWED: Allows TRANSPORT to delay transmission to group the message with other messages into a larger batch to reduce the number of packets sent.
GNUNET_MQ_PREF_GOODPUT: Directs TRANSPORT to select the highest goodput channel available.
GNUNET_MQ_PREF_OUT_OF_ORDER: Allows TRANSPORT to reorder the messages as it sees fit, otherwise TRANSPORT should attempt to preserve transmission order.
Each MQ envelope is always able to store those options (and the
priority), and in the future this uniform API will be used by TRANSPORT,
CORE, CADET and possibly other subsystems that send messages (like
LAKE). When CORE sets preferences and priorities, it is supposed to
respect the preferences and priorities it is given from higher layers.
Similarly, CADET also simply passes on the preferences and priorities of
the layer above CADET. When a layer combines multiple smaller messages
into one larger transmission, the GNUNET_MQ_env_combine_options()
should be used to calculate options for the combined message. We note
that the exact semantics of the options may differ by layer. For
example, CADET will always strictly implement reliable and in-order
delivery of messages, while the same options are only advisory for
TRANSPORT and CORE: they should try (using ACKs on unreliable
communicators, not changing the message order themselves), but if
messages are lost anyway (e.g. because a TCP is dropped in the middle),
or if messages are reordered (e.g. because they took different paths
over the network and arrived in a different order) TRANSPORT and CORE do
not have to correct this. Whether a preference is strict or loose is
thus dened by the respective layer.
Communicators
The API for communicators is defined in
gnunet_transport_communication_service.h. Each communicator must
specify its (global) communication characteristics, which for now only
say whether the communication is reliable (e.g. TCP, HTTPS) or
unreliable (e.g. UDP, WLAN). Each communicator must specify a unique
address prex, or NULL if the communicator cannot establish outgoing
connections (for example because it is only acting as a TCP server). A
communicator must tell TRANSPORT which addresses it is reachable under.
Addresses may be added or removed at any time. A communicator may have
zero addresses (transmission only). Addresses do not have to match the
address prefix.
TRANSPORT may ask a communicator to try to connect to another address. TRANSPORT will only ask for connections where the address matches the communicator’s address prefix that was provided when the connection was established. Communicators should then attempt to establish a connection. It is under the discretion of the communicator whether to honor this request. Reasons for not honoring such a request may be that an existing connection exists or resource limitations. No response is provided to TRANSPORT service on failure. The TRANSPORT service has to ask the communicator explicitly to retry.
If a communicator succeeds in establishing an outgoing connection for transmission, or if a communicator receives an incoming bi-directional connection, the communicator must inform the TRANSPORT service that a message queue (MQ) for transmission is now available. For that MQ, the communicator must provide the peer identity claimed by the other end. It must also provide a human-readable address (for debugging) and a maximum transfer unit (MTU). A MTU of zero means sending is not supported, SIZE_MAX should be used for no MTU. The communicator should also tell TRANSPORT what network type is used for the queue. The communicator may tell TRANSPORT anytime that the queue was deleted and is no longer available.
The communicator API also provides for flow control. First,
communicators exhibit back-pressure on TRANSPORT: the number of messages
TRANSPORT may add to a queue for transmission will be limited. So by not
draining the transmission queue, back-pressure is provided to TRANSPORT.
In the other direction, communicators may allow TRANSPORT to give
back-pressure towards the communicator by providing a non-NULL
GNUNET_TRANSPORT_MessageCompletedCallback argument to the
GNUNET_TRANSPORT_communicator_receive function. In this case,
TRANSPORT will only invoke this function once it has processed the
message and is ready to receive more. Communicators should then limit
how much traffic they receive based on this backpressure. Note that
communicators do not have to provide a
GNUNET_TRANSPORT_MessageCompletedCallback; for example, UDP cannot
support back-pressure due to the nature of the UDP protocol. In this
case, TRANSPORT will implement its own TRANSPORT-to-TRANSPORT flow
control to reduce the sender’s data rate to acceptable levels.
TRANSPORT may notify a communicator about backchannel messages TRANSPORT received from other peers for this communicator. Similarly, communicators can ask TRANSPORT to try to send a backchannel message to other communicators of other peers. The semantics of the backchannel message are up to the communicators which use them. TRANSPORT may fail transmitting backchannel messages, and TRANSPORT will not attempt to retransmit them.
UDP communicator
The UDP communicator implements a basic encryption layer to protect from metadata leakage. The layer tries to establish a shared secret using an Elliptic-Curve Diffie-Hellman key exchange in which the initiator of a packet creates an ephemeral key pair to encrypt a message for the target peer identity. The communicator always offers this kind of transmission queue to a (reachable) peer in which messages are encrypted with dedicated keys. The performance of this queue is not suitable for high volume data transfer.
If the UDP connection is bi-directional, or the TRANSPORT is able to offer a backchannel connection, the resulting key can be re-used if the recieving peer is able to ACK the reception. This will cause the communicator to offer a new queue (with a higher priority than the default queue) to TRANSPORT with a limited capacity. The capacity is increased whenever the communicator receives an ACK for a transmission. This queue is suitable for high-volume data transfer and TRANSPORT will likely prioritize this queue (if available).
Communicators that try to establish a connection to a target peer authenticate their peer ID (public key) in the first packets by signing a monotonic time stamp, its peer ID, and the target peerID and send this data as well as the signature in one of the first packets. Receivers should keep track (persist) of the monotonic time stamps for each peer ID to reject possible replay attacks.
FIXME: Handshake wire format? KX, Flow.
TCP communicator
FIXME: Handshake wire format? KX, Flow.
QUIC communicator
The QUIC communicator runs over a bi-directional UDP connection. TLS layer with self-signed certificates (binding/signed with peer ID?). Single, bi-directional stream? FIXME: Handshake wire format? KX, Flow.
TRANSPORT — Overlay transport management
This chapter documents how the GNUnet transport subsystem works. The GNUnet transport subsystem consists of three main components: the transport API (the interface used by the rest of the system to access the transport service), the transport service itself (most of the interesting functions, such as choosing transports, happens here) and the transport plugins. A transport plugin is a concrete implementation for how two GNUnet peers communicate; many plugins exist, for example for communication via TCP, UDP, HTTP, HTTPS and others. Finally, the transport subsystem uses supporting code, especially the NAT/UPnP library to help with tasks such as NAT traversal.
Key tasks of the transport service include:
Create our HELLO message, notify clients and neighbours if our HELLO changes (using NAT library as necessary)
Validate HELLOs from other peers (send PING), allow other peers to validate our HELLO’s addresses (send PONG)
Upon request, establish connections to other peers (using address selection from ATS subsystem) and maintain them (again using PINGs and PONGs) as long as desired
Accept incoming connections, give ATS service the opportunity to switch communication channels
Notify clients about peers that have connected to us or that have been disconnected from us
If a (stateful) connection goes down unexpectedly (without explicit DISCONNECT), quickly attempt to recover (without notifying clients) but do notify clients quickly if reconnecting fails
Send (payload) messages arriving from clients to other peers via transport plugins and receive messages from other peers, forwarding those to clients
Enforce inbound traffic limits (using flow-control if it is applicable); outbound traffic limits are enforced by CORE, not by us (!)
Enforce restrictions on P2P connection as specified by the blacklist configuration and blacklisting clients
Note that the term "clients" in the list above really refers to the GNUnet-CORE service, as CORE is typically the only client of the transport service.
SET — Peer to peer set operations (Deprecated)
Note
The SET subsystem is in process of being replaced by the SETU and SETI subsystems, which provide basically the same functionality, just using two different subsystems. SETI and SETU should be used for new code.
The SET service implements efficient set operations between two peers over a CADET tunnel. Currently, set union and set intersection are the only supported operations. Elements of a set consist of an element type and arbitrary binary data. The size of an element’s data is limited to around 62 KB.
Local Sets
Sets created by a local client can be modified and reused for multiple operations. As each set operation requires potentially expensive special auxiliary data to be computed for each element of a set, a set can only participate in one type of set operation (either union or intersection). The type of a set is determined upon its creation. If a the elements of a set are needed for an operation of a different type, all of the set’s element must be copied to a new set of appropriate type.
Set Modifications
Even when set operations are active, one can add to and remove elements from a set. However, these changes will only be visible to operations that have been created after the changes have taken place. That is, every set operation only sees a snapshot of the set from the time the operation was started. This mechanism is not implemented by copying the whole set, but by attaching generation information to each element and operation.
Set Operations
Set operations can be started in two ways: Either by accepting an operation request from a remote peer, or by requesting a set operation from a remote peer. Set operations are uniquely identified by the involved peers, an application id and the operation type.
The client is notified of incoming set operations by set listeners. A set listener listens for incoming operations of a specific operation type and application id. Once notified of an incoming set request, the client can accept the set request (providing a local set for the operation) or reject it.
Result Elements
The SET service has three result modes that determine how an operation’s result set is delivered to the client:
Full Result Set. All elements of set resulting from the set operation are returned to the client.
Added Elements. Only elements that result from the operation and are not already in the local peer’s set are returned. Note that for some operations (like set intersection) this result mode will never return any elements. This can be useful if only the remove peer is actually interested in the result of the set operation.
Removed Elements. Only elements that are in the local peer’s initial set but not in the operation’s result set are returned. Note that for some operations (like set union) this result mode will never return any elements. This can be useful if only the remove peer is actually interested in the result of the set operation.
SETI — Peer to peer set intersections
The SETI service implements efficient set intersection between two peers over a CADET tunnel. Elements of a set consist of an element type and arbitrary binary data. The size of an element’s data is limited to around 62 KB.
Intersection Sets
Sets created by a local client can be modified (by adding additional elements) and reused for multiple operations. If elements are to be removed, a fresh set must be created by the client.
Set Intersection Modifications
Even when set operations are active, one can add elements to a set. However, these changes will only be visible to operations that have been created after the changes have taken place. That is, every set operation only sees a snapshot of the set from the time the operation was started. This mechanism is not implemented by copying the whole set, but by attaching generation information to each element and operation.
Set Intersection Operations
Set operations can be started in two ways: Either by accepting an operation request from a remote peer, or by requesting a set operation from a remote peer. Set operations are uniquely identified by the involved peers, an application id and the operation type.
The client is notified of incoming set operations by set listeners. A set listener listens for incoming operations of a specific operation type and application id. Once notified of an incoming set request, the client can accept the set request (providing a local set for the operation) or reject it.
Intersection Result Elements
The SET service has two result modes that determine how an operation’s result set is delivered to the client:
Return intersection. All elements of set resulting from the set intersection are returned to the client.
Removed Elements. Only elements that are in the local peer’s initial set but not in the intersection are returned.
SETU — Peer to peer set unions
The SETU service implements efficient set union operations between two peers over a CADET tunnel. Elements of a set consist of an element type and arbitrary binary data. The size of an element’s data is limited to around 62 KB.
Union Sets
Sets created by a local client can be modified (by adding additional elements) and reused for multiple operations. If elements are to be removed, a fresh set must be created by the client.
Set Union Modifications
Even when set operations are active, one can add elements to a set. However, these changes will only be visible to operations that have been created after the changes have taken place. That is, every set operation only sees a snapshot of the set from the time the operation was started. This mechanism is not implemented by copying the whole set, but by attaching generation information to each element and operation.
Set Union Operations
Set operations can be started in two ways: Either by accepting an operation request from a remote peer, or by requesting a set operation from a remote peer. Set operations are uniquely identified by the involved peers, an application id and the operation type.
The client is notified of incoming set operations by set listeners. A set listener listens for incoming operations of a specific operation type and application id. Once notified of an incoming set request, the client can accept the set request (providing a local set for the operation) or reject it.
Union Result Elements
The SET service has three result modes that determine how an operation’s result set is delivered to the client:
Locally added Elements. Elements that are in the union but not already in the local peer’s set are returned.
Remote added Elements. Additionally, notify the client if the remote peer lacked some elements and thus also return to the local client those elements that we are sending to the remote peer to be added to its union. Obtaining these elements requires setting the
GNUNET_SETU_OPTION_SYMMETRICoption.